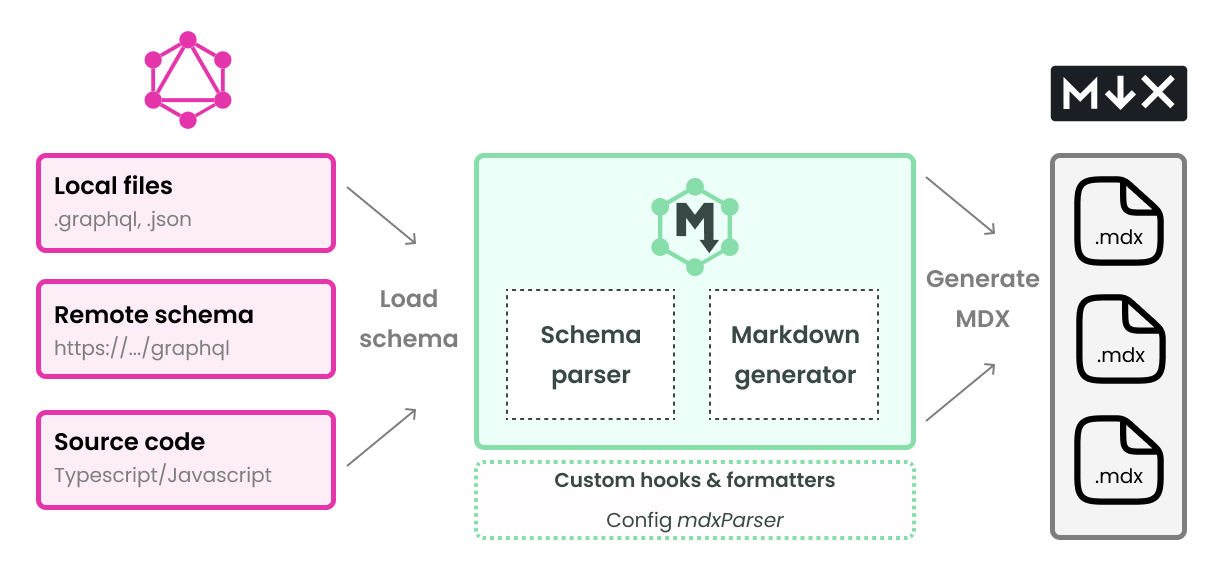
How It Works
GraphQL-Markdown reads your schema, parses every type and operation, and writes one MDX file per type category — ready to publish with Docusaurus or any MDX framework.
Pipeline
Input
Given this schema:
type User {
"""User's unique identifier"""
id: ID!
"""User's full name"""
name: String!
"""List of posts authored by this user"""
posts: [Post!]
}
type Post {
id: ID!
title: String!
author: User!
}
type Query {
getUser(id: ID!): User
getPosts: [Post!]!
}
Output
GraphQL-Markdown generates a file per type category. For example, objects/user.mdx:
---
id: user
title: User
---
# User
Object Type
## Fields
| Name | Type | Description |
| ---- | ---- | ----------- |
| `id` | `ID!` | User's unique identifier |
| `name` | `String!` | User's full name |
| `posts` | [`[Post!]`](/docs/graphql/objects/post) | List of posts authored by this user |
## Returned by
[`getUser`](/docs/graphql/queries/get-user)
Notice the cross-link on Post and the back-reference under "Returned by" — these are generated automatically from the schema graph.
What gets generated
| Output | Description |
|---|---|
objects/ | One file per Object type |
inputs/ | One file per Input type |
queries/ | One file per Query field |
mutations/ | One file per Mutation field |
subscriptions/ | One file per Subscription field |
enums/ | One file per Enum type |
interfaces/ | One file per Interface type |
unions/ | One file per Union type |
scalars/ | One file per Scalar type |
_category_.yml | Sidebar metadata for each folder |
Customization
The generation pipeline exposes lifecycle hooks at every stage — before/after schema load, before/after rendering each type, before/after composing each page. See hook recipes and custom directives.
To see the full output in action, browse the live examples.